 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDi-BiLPS: Denoising induced Bidirectional Latent-PDE-Solver under Sparse Observations
May 13, 2026Partial differential equations (PDEs) are fundamental for modeling complex natural and physical phenomena. In many real-world applications, however, observational data are extremely sparse, which severely limits the applicability of both classical numerical solvers and existing neural approaches. While neural methods have shown promising results under moderately sparse observations, their inference efficiency at high resolutions is limited, and their accuracy degrades substantially in the extremely sparse regime. In this work, we propose the Di-BiLPS, a unified neural framework that effectively handle both forward and inverse PDE problems under extremely sparse observations. Di-BiLPS combines a variational autoencoder to compress high-dimensional inputs into a compact latent space, a latent diffusion module to model uncertainty, and contrastive learning to align representations. Operating entirely in this latent space, the framework achieves efficient inference while retaining flexible input-output mapping. In addition, we introduce a PDE-informed denoising algorithm based on a variance-preserving diffusion process, which further improves inference efficiency. Extensive experiments on multiple PDE benchmarks demonstrate that Di-BiLPS consistently achieves SOTA performance under extremely sparse inputs (as low as 3%), while substantially reducing computational cost. Moreover, Di-BiLPS enables zero-shot super-resolution, as it allows predictions over continuous spatial-temporal domains.
Unveiling Language Routing Isolation in Multilingual MoE Models for Interpretable Subnetwork Adaptation
Apr 04, 2026Mixture-of-Experts (MoE) models exhibit striking performance disparities across languages, yet the internal mechanisms driving these gaps remain poorly understood. In this work, we conduct a systematic analysis of expert routing patterns in MoE models, revealing a phenomenon we term Language Routing Isolation, in which high- and low-resource languages tend to activate largely disjoint expert sets. Through layer-stratified analysis, we further show that routing patterns exhibit a layer-wise convergence-divergence pattern across model depth. Building on these findings, we propose RISE (Routing Isolation-guided Subnetwork Enhancement), a framework that exploits routing isolation to identify and adapt language-specific expert subnetworks. RISE applies a tripartite selection strategy, using specificity scores to identify language-specific experts in shallow and deep layers and overlap scores to select universal experts in middle layers. By training only the selected subnetwork while freezing all other parameters, RISE substantially improves low-resource language performance while preserving capabilities in other languages. Experiments on 10 languages demonstrate that RISE achieves target-language F1 gains of up to 10.85% with minimal cross-lingual degradation.
TreeHop: Generate and Filter Next Query Embeddings Efficiently for Multi-hop Question Answering
Apr 30, 2025



Retrieval-augmented generation (RAG) systems face significant challenges in multi-hop question answering (MHQA), where complex queries require synthesizing information across multiple document chunks. Existing approaches typically rely on iterative LLM-based query rewriting and routing, resulting in high computational costs due to repeated LLM invocations and multi-stage processes. To address these limitations, we propose TreeHop, an embedding-level framework without the need for LLMs in query refinement. TreeHop dynamically updates query embeddings by fusing semantic information from prior queries and retrieved documents, enabling iterative retrieval through embedding-space operations alone. This method replaces the traditional "Retrieve-Rewrite-Vectorize-Retrieve" cycle with a streamlined "Retrieve-Embed-Retrieve" loop, significantly reducing computational overhead. Moreover, a rule-based stop criterion is introduced to further prune redundant retrievals, balancing efficiency and recall rate. Experimental results show that TreeHop rivals advanced RAG methods across three open-domain MHQA datasets, achieving comparable performance with only 5\%-0.4\% of the model parameter size and reducing the query latency by approximately 99\% compared to concurrent approaches. This makes TreeHop a faster and more cost-effective solution for deployment in a range of knowledge-intensive applications. For reproducibility purposes, codes and data are available here: https://github.com/allen-li1231/TreeHop-RAG.
SFi-Former: Sparse Flow Induced Attention for Graph Transformer
Apr 29, 2025Graph Transformers (GTs) have demonstrated superior performance compared to traditional message-passing graph neural networks in many studies, especially in processing graph data with long-range dependencies. However, GTs tend to suffer from weak inductive bias, overfitting and over-globalizing problems due to the dense attention. In this paper, we introduce SFi-attention, a novel attention mechanism designed to learn sparse pattern by minimizing an energy function based on network flows with l1-norm regularization, to relieve those issues caused by dense attention. Furthermore, SFi-Former is accordingly devised which can leverage the sparse attention pattern of SFi-attention to generate sparse network flows beyond adjacency matrix of graph data. Specifically, SFi-Former aggregates features selectively from other nodes through flexible adaptation of the sparse attention, leading to a more robust model. We validate our SFi-Former on various graph datasets, especially those graph data exhibiting long-range dependencies. Experimental results show that our SFi-Former obtains competitive performance on GNN Benchmark datasets and SOTA performance on LongRange Graph Benchmark (LRGB) datasets. Additionally, our model gives rise to smaller generalization gaps, which indicates that it is less prone to over-fitting. Click here for codes.
JTreeformer: Graph-Transformer via Latent-Diffusion Model for Molecular Generation
Apr 29, 2025The discovery of new molecules based on the original chemical molecule distributions is of great importance in medicine. The graph transformer, with its advantages of high performance and scalability compared to traditional graph networks, has been widely explored in recent research for applications of graph structures. However, current transformer-based graph decoders struggle to effectively utilize graph information, which limits their capacity to leverage only sequences of nodes rather than the complex topological structures of molecule graphs. This paper focuses on building a graph transformer-based framework for molecular generation, which we call \textbf{JTreeformer} as it transforms graph generation into junction tree generation. It combines GCN parallel with multi-head attention as the encoder. It integrates a directed acyclic GCN into a graph-based Transformer to serve as a decoder, which can iteratively synthesize the entire molecule by leveraging information from the partially constructed molecular structure at each step. In addition, a diffusion model is inserted in the latent space generated by the encoder, to enhance the efficiency and effectiveness of sampling further. The empirical results demonstrate that our novel framework outperforms existing molecule generation methods, thus offering a promising tool to advance drug discovery (https://anonymous.4open.science/r/JTreeformer-C74C).
Reasoning Factual Knowledge in Structured Data with Large Language Models
Aug 22, 2024



Large language models (LLMs) have made remarkable progress in various natural language processing tasks as a benefit of their capability to comprehend and reason with factual knowledge. However, a significant amount of factual knowledge is stored in structured data, which possesses unique characteristics that differ from the unstructured texts used for pretraining. This difference can introduce imperceptible inference parameter deviations, posing challenges for LLMs in effectively utilizing and reasoning with structured data to accurately infer factual knowledge. To this end, we propose a benchmark named StructFact, to evaluate the structural reasoning capabilities of LLMs in inferring factual knowledge. StructFact comprises 8,340 factual questions encompassing various tasks, domains, timelines, and regions. This benchmark allows us to investigate the capability of LLMs across five factual tasks derived from the unique characteristics of structural facts. Extensive experiments on a set of LLMs with different training strategies reveal the limitations of current LLMs in inferring factual knowledge from structured data. We present this benchmark as a compass to navigate the strengths and weaknesses of LLMs in reasoning with structured data for knowledge-sensitive tasks, and to encourage advancements in related real-world applications. Please find our code at https://github.com/EganGu/StructFact.
Refiner: Restructure Retrieval Content Efficiently to Advance Question-Answering Capabilities
Jun 18, 2024



Large Language Models (LLMs) are limited by their parametric knowledge, leading to hallucinations in knowledge-extensive tasks. To address this, Retrieval-Augmented Generation (RAG) incorporates external document chunks to expand LLM knowledge. Furthermore, compressing information from document chunks through extraction or summarization can improve LLM performance. Nonetheless, LLMs still struggle to notice and utilize scattered key information, a problem known as the "lost-in-the-middle" syndrome. Therefore, we typically need to restructure the content for LLM to recognize the key information. We propose $\textit{Refiner}$, an end-to-end extract-and-restructure paradigm that operates in the post-retrieval process of RAG. $\textit{Refiner}$ leverages a single decoder-only LLM to adaptively extract query-relevant contents verbatim along with the necessary context, and section them based on their interconnectedness, thereby highlights information distinction, and aligns downstream LLMs with the original context effectively. Experiments show that a trained $\textit{Refiner}$ (with 7B parameters) exhibits significant gain to downstream LLM in improving answer accuracy, and outperforms other state-of-the-art advanced RAG and concurrent compressing approaches in various single-hop and multi-hop QA tasks. Notably, $\textit{Refiner}$ achieves a 80.5% tokens reduction and a 1.6-7.0% improvement margin in multi-hop tasks compared to the next best solution. $\textit{Refiner}$ is a plug-and-play solution that can be seamlessly integrated with RAG systems, facilitating its application across diverse open-source frameworks.
Towards High-fidelity Singing Voice Conversion with Acoustic Reference and Contrastive Predictive Coding
Oct 10, 2021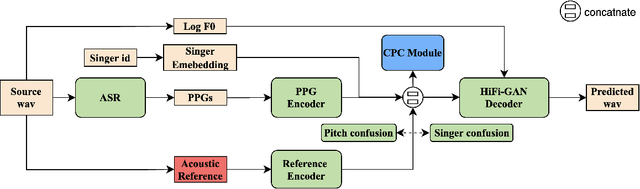
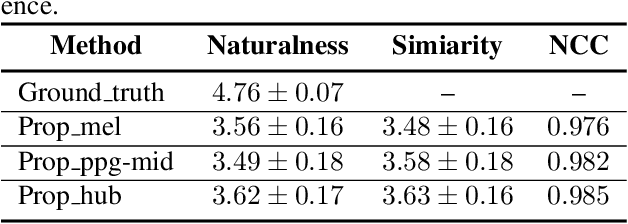
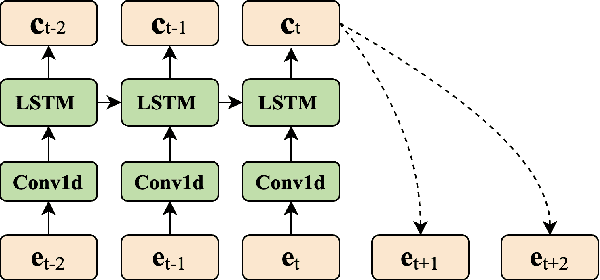

Recently, phonetic posteriorgrams (PPGs) based methods have been quite popular in non-parallel singing voice conversion systems. However, due to the lack of acoustic information in PPGs, style and naturalness of the converted singing voices are still limited. To solve these problems, in this paper, we utilize an acoustic reference encoder to implicitly model singing characteristics. We experiment with different auxiliary features, including mel spectrograms, HuBERT, and the middle hidden feature (PPG-Mid) of pretrained automatic speech recognition (ASR) model, as the input of the reference encoder, and finally find the HuBERT feature is the best choice. In addition, we use contrastive predictive coding (CPC) module to further smooth the voices by predicting future observations in latent space. Experiments show that, compared with the baseline models, our proposed model can significantly improve the naturalness of converted singing voices and the similarity with the target singer. Moreover, our proposed model can also make the speakers with just speech data sing.
PPG-based singing voice conversion with adversarial representation learning
Oct 28, 2020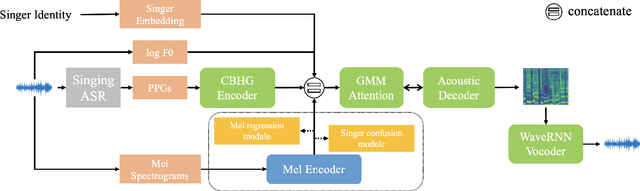
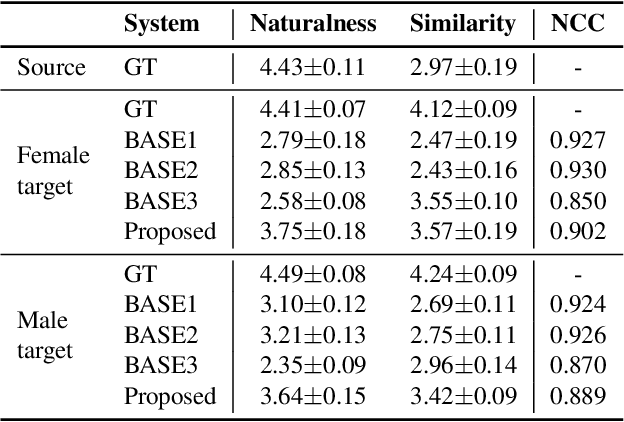
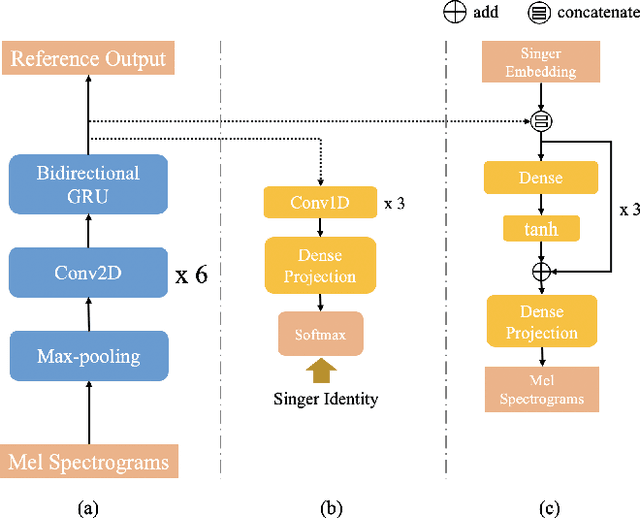
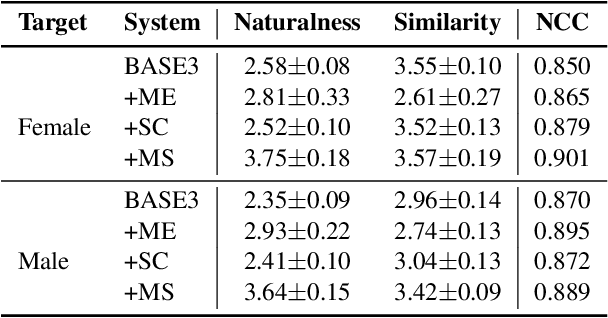
Singing voice conversion (SVC) aims to convert the voice of one singer to that of other singers while keeping the singing content and melody. On top of recent voice conversion works, we propose a novel model to steadily convert songs while keeping their naturalness and intonation. We build an end-to-end architecture, taking phonetic posteriorgrams (PPGs) as inputs and generating mel spectrograms. Specifically, we implement two separate encoders: one encodes PPGs as content, and the other compresses mel spectrograms to supply acoustic and musical information. To improve the performance on timbre and melody, an adversarial singer confusion module and a mel-regressive representation learning module are designed for the model. Objective and subjective experiments are conducted on our private Chinese singing corpus. Comparing with the baselines, our methods can significantly improve the conversion performance in terms of naturalness, melody, and voice similarity. Moreover, our PPG-based method is proved to be robust for noisy sources.